MarianNMT
Fast Neural Machine Translation in C++
Is MT really lexically less diverse than human translation?
What got me interested in lexical diversity of MT outputs?
This blog post describes my journey into the rabbit hole (actually now it’s a giant ground sloth burrow) that is lexical diversity of machine translation outputs. I got interested in the topic after attending MT Summit 2019 in Dublin last year and listening to two intriguing talks, one by Eva Vanmassenhove (Vanmassenhove et al. 2019 ) and one by Antonio Toral (Toral 2019) – who then went on to win the best paper award at that conference for his talk.
Both papers conclude – among other observations – that machine translation outputs demonstrate lower lexical diversity as measured by various existing metrics than human translations. Machine translation and human translations in turn demonstrate lower lexical diversity than human-written text that was naturally composed in the same target language. I like both papers a lot for the approaches they take in analyzing their data, but both have problems in their choice of analyzed MT systems and modeling decisions. Vanmassenhove et al. (2019) create MT systems that due to smaller data and lack of subword segmentation are likely to show lower lexical diversity, more on that below. Toral (2019) includes a number of state-of-the-art systems (at their time of creation), but in my opinion too few to be able to infer that MT is generally lexically less diverse than human translations (the main focus of that work is Post-Editese though). Toral (2019) compares 18 systems on 6 language pairs, one of them can be considered close to current state-of-the-art (zh-en). Vanmassenhove et al. (2019) look at two translation directions (en-fr, en-es) with small training corpora (ca. 1 million sentences) and three MT flavors (SMT, NMT-RNN, NMT-Transformer) with and without back-translation, 12 systems altogether.
Correction: I wrote in an earlier version of the post that Vanmassenhove et al. (2019) used 100K sentences of training data; that is incorrect. I looked at the wrong table and mixed up vocabulary size and training data size.
The research questions in these two papers sparked my interest, but I am mostly curious if lexical diversity (LD) – this apparently easily measurable property – can be used for something practical. If LD indeed reliably separates natural text from human translationese and human translationese from machine translationese as these works suggest then there might be applications to identifying machine-translated content in large parallel corpora or at least the directionality of human translations (looking at gradients of LD on both sides compared to other document pairs with gradients pointing in other directions). Or we might be able to subselect training corpora to have larger LD, potentially increasing the LD of our MT systems if that is actually a desired property. To get a better feeling for LD, let’s go large-scale!
WMT or it didn’t happen!
I have been vocally critical of work that uses artificially small data for testing research hypotheses. By “artificially small” I mean cases where lots of data is actually available, but only a small corpus is chosen for experiments with little to no justification. I am also of the opinion that questions about capabilities of MT have to be measured on capable MT models. Toy models trained on toy data result in toy answers.
For this analysis, I reached for WMT19 outputs which give us a good mix of high and low-resource systems, including current large MT online engines. For WMT19 alone, I am looking at 14 translation directions and over 180 MT systems. It also gives me lots of test sets, results of human evaluation and even more historical data from previous years. We can assume that the best of the best is taking part in WMT. So much for the good part. We also have to be careful with overstating the results that we will gain from this. We are looking at only one domain (news) and WMT has a specific way of creating their test sets. There has been quite a bit of a debate concerning the quality of WMT test sets and the process involved. This needs to be emphasized as potential problems.
New: Lexical diversity metrics and variable-quality MT
Both, Toral (2019) and Vanmassenhove et al. (2019), use type-token ratio (TTR) as one of their metrics; Vanmassenhove et al. (2019) also computes numbers for Yule’s K (citation needed) and MTLD (measure of textual lexical diversity, McCarthy 2005: An assessment of the range and usefulness of lexical diversity measures and the potential of the measure of textual, lexical diversity (MTLD)) and McCarthy and Jarvis 2010).
I will use TTR and MTLD in this post. The naive implementation of TTR is trivial. Type-token ratio is just the number of unique lexical items in the text divided by the number of running tokens. For data sets of the same length this is probably a reasonable diversity measure, MT outputs however can differ in length, for WMT test sets by multiple hundreds of words.
For my naive MTLD version, I followed the explanation and good example from Koizumi (2012). TTR scores decrease for longer texts which makes them incomparable across different documents. MTLD is meant to fix that:
- MTLD counts the number of times (factors) the running TTR of a text moving from left to right drops below the magic number 0.72;
- Whenever that happens we reset the type/tokens counts. Segments shorter than 10 tokens don’t get counted as factors;
- When we reach the end of a document the remaining TTR score larger than 0.72 gets turned into
(1 - TTR) / (1 - 0.72)(percentage of lexical diversity loss) and added to the number of factors. - Next we divide the total number of tokens of the document by the factor (this means perfect lexical diversity (one type per token) achieves an MTLD score of
+infor is undefined as the factor remains 0); - We repeat the same process with the reversed text (going from right to left) and average the two directions.
The intuition seems to be that a lexically diverse text will have fewer regions where the TTR score dropped below 0.72 than a lexically less diverse text. The restriction to regions should make the measure more robust to varying length.
One aspect I didn’t think about in the first version of this post is that these measures have been applied mostly to human-authored text. I just went ahead and applied them to MT output. However, as readers on Twitter were right to point out (shout out to Bram Vanroy and Karin Sim) the errors that MT systems make – e.g. spurious copies from the source, hallucinated words due to subwords, wrong translations – may strongly influence the lexical diversity measures. I think we can ignore wrong translations, it seems to me this is a separate problem that needs to be captured by other means and we are doing this below to some degree by looking at the correlation of LD with human eval. However, incorrect copies and generated non-words are most definitely something we need to at least guard against.
What are Toral (2019) and Vanmassenhove et al. (2019) doing in this regard? I think Toral (2019) ignores the problem as I did at first, but he is in a better position than me: his MT systems have lower LD already, so he does not have to worry about unfairly disadvantaging the human reference – if anything, the LD of the machines could probably only decrease. His hypothesis is going to be confirmed anyway.
Vanmassenhove et al. (2019) do something clever (which I didn’t realize while writing about that in the first version of the post): they side-step the problem by not using subwords. This helps them to nearly completely avoid the spurious copy and hallucinated words issue (the SMT system can still copy, it’s built into the decoder). So, measurement-wise they are golden, no noise to worry about.
However, that comes at a cost: disabling the source of noise for NMT by not using subwords means they also disabled the NMT system’s ability to do creative word formation and morphology, as well as transliteration or justified copying and unknown word handling. These are clearly mechanisms that are responsible for potentially increased lexical diversity. Assuming a beneficial word to noise ratio for subwords in general (otherwise, why would we use them?), that would mean that an NMT system without subwords is likely operating at a lower bound of capability to generate lexically diverse output compared to similar systems with subwords. This is further excerbated by the now huge softmax distribution over the target vocabulary (>100K items from a relatively small training corpus with many undertrained long tail observations). Note how this is more problematic than the situation from Toral (2019): there the MT systems are potentially at an advantage due to ignoring the noise, but they are measured to be lower than human-created translations anyway, so all is good. Here the MT system outputs are measured to have lower LD than the human translations, but the modeling decisions put that at a lower bound for potential MT systems. The reported numbers are correct for the given systems, but we probably cannot generalize based on that to any other MT systems unless they have been trained in a similar way.
So, how do we measure the LD of practical MT systems then? I am proposing the following modifications to either TTR or MTLD (works for both) for machine translation:
- Copy-aware LD (cTTR, cMTLD): For every line in the target text, inspect the corresponding source line and replace matching target tokens with a
<COPY>symbol. Proceed to compute the LD measure as before, now with the substitions. - Lexicalized copy-aware LD (lcTTR, lcMTLD): As above, but add a very large list of target words and corresponding frequencies. We replace target tokens with an
<UNK>symbol if its frequency is below a certain threshold. As for copies, we keep certain copies if their frequency is above another threshold instead of using<COPY>– this is meant to allow for copies that are actually legitimate target language words. Next we need to compute LD with the substituted tokens.
The GitHub repository contains all the code required to repeat the experiments and to recreate the figures in this post. To compute the LD measures, I extract all continuous Unicode letter strings as tokens and lowercase them. Punctuation and numbers are ignored. For Chinese as a target language I separate them into single glyphs, that might be suboptimal.
The lexicalized versions have problems I haven’t solved yet: among the WMT languages, it’s only easily and reliably applicable for English as a target language (should also work well enough for Romance languages). All the other languages in the mix have either very productive morphology and word formation or non-latin scripts. All that doesn’t go well with word list based exclusion and I do not have the patience to deal with that situation (sorry, it’s just a blog post, folks).
For the English frequency list I collected counts from all of WMT monolingual English news data. I set the minimal frequency for valid target vocabulary items to 5 (1M vocabulary items remain) and the threshold for allowed copies to 1000 (50K items). No good justification here, these are nice round numbers and when I looked through the included/excluded words it seemed decent enough.
| lcTTR | MTLD | lcMTLD | |
|---|---|---|---|
| TTR | 0.83 | 0.46 | 0.13 |
| lcTTR | - | 0.27 | 0.31 |
| MTLD | - | - | 0.71 |
The table above shows correlation coefficients between non-modified and lexicalized copy-aware version for translations into English; and below for specific language pairs. Clearly the denoising has strong effects on some of the language pairs. While looking through the results, it’s mostly a couple of low-quality systems flipping from very high LD to very low LD. For instance one LT-EN system seems to generate a lot of Gujarati (multi-lingual system?). The word list eliminates all of that. Also, the strong language pairs are seemingly unaffected by noise.
| de-en | fi-en | gu-en | kk-en | lt-en | ru-en | zh-en | |
|---|---|---|---|---|---|---|---|
| cor(TTR,lcTTR) | 0.96 | 0.67 | 0.75 | 0.18 | 0.54 | -0.13 | 0.99 |
| cor(MTLD,lcMTLD) | 0.95 | 0.46 | 0.75 | -0.24 | -0.39 | 0.82 | 0.99 |
I am again omitting numbers for EN-* out of laziness. Here we do not have the word list and the results would be a lot less trustable, maybe with the exception of German. For translations into English, we will use lcTTR/lcMTLD, out of English cTTR/cMTLD. Let’s move on to actual results.
Lexical diversity results for WMT19 systems
So, let’s first look at (l)cTTR for all the WMT19 translation directions and the human-created references. Below (click the image for full size) you can see one box plot per translation direction. The red dot marks the LD of the human reference set. The box plot spans multiple MT systems from most to least lexically diverse as measured by (l)cTTR.
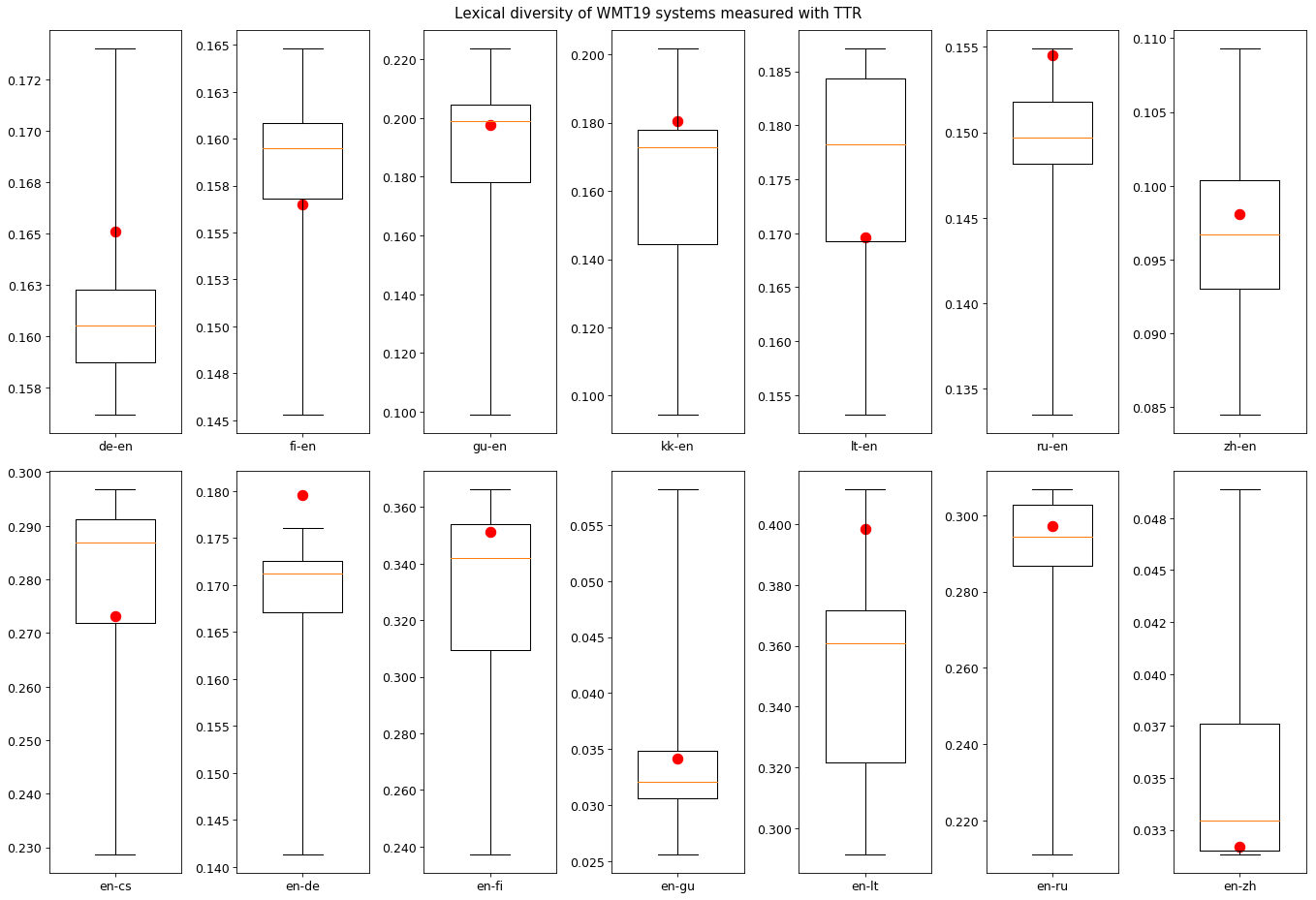
We can see immediately that only in one case the human reference is the most lexically diverse according to the partially denoised metric (en-de). There are usually a couple of MT systems in the competition that display more lexical diversity than the human reference. In some cases the majority of MT systems is more diverse than the reference; This is interesting. For WMT19 at least, it seems there would be no reliable way to successfully tell apart MT from the human translated test set using (l)cTTR as a measure. Again, the results for translation into English are probably reliable, so should be EN-DE.
Additional results and plots:
- box plot with (l)cMTLD
- box plot with TTR (no denoising, old results)
- box plot with MTLD (no denoising)
{kind=link}
{kind=link}
{kind=link}
It seems that denoising moves the references up in the box plots but not high enough to escape the previous observations. Also MTLD variants seem to see the references as more diverse than TTR variants.
Does lexical diversity correlate with human-perceived quality?
During the discussion time after the mentioned talks, the question of the meaning of lexical diversity was raised. Is higher LD actually better in general? Does lower LD stand for more consistency etc. Can we draw conclusions about lexical diversity and translation quality? Are more diverse MT outputs better than less diverse ones? Luckily, we can use WMT19 data to shed some light at that question as well. The system-level human judgments are available for download and we are looking at normalized z-Scores (x-axis) versus (l)cTTR (y-axis) for all language pairs in the figure below (click for full size).
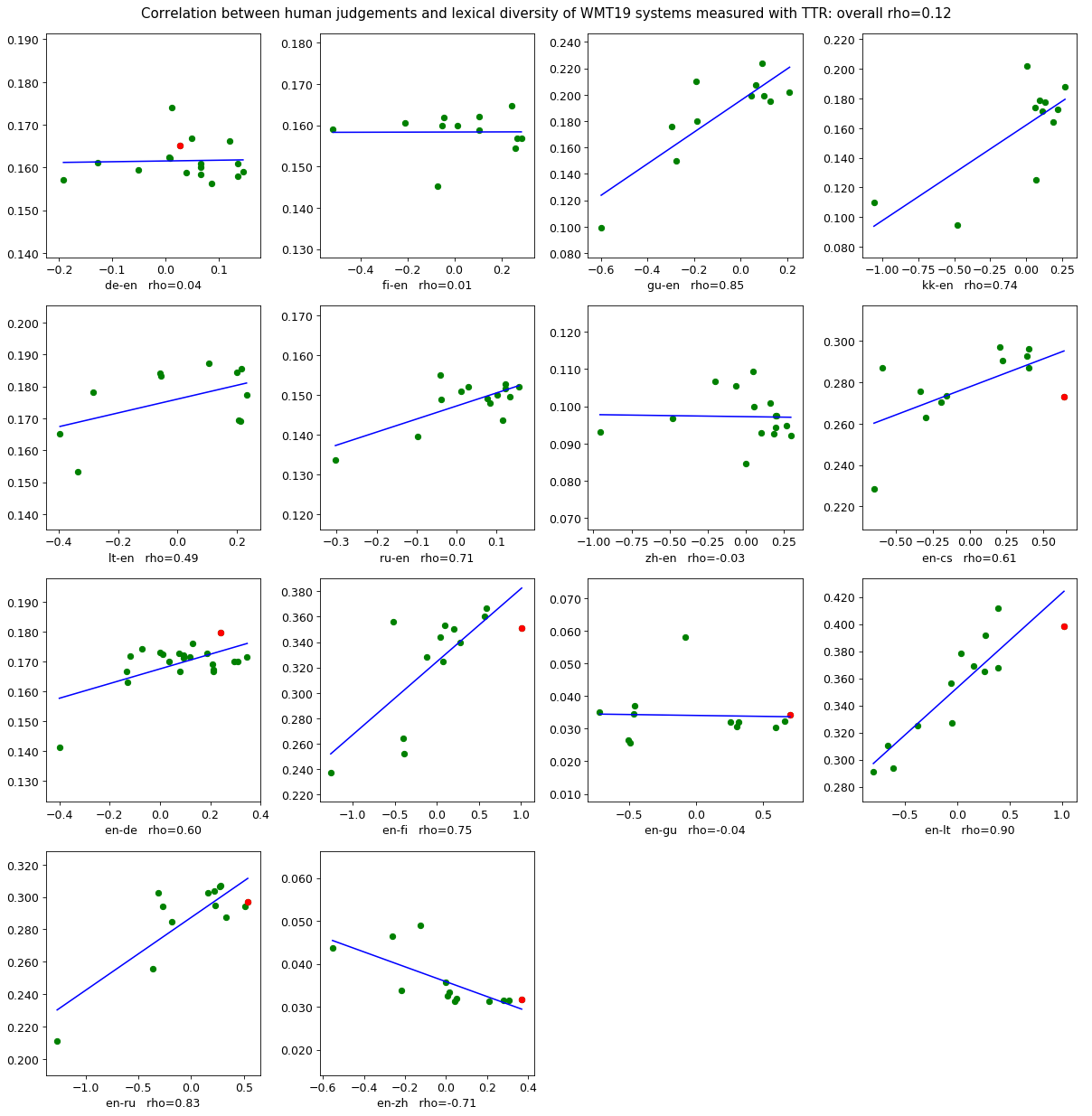
Additional results and plots:
Green marks are MT systems, the red mark is the reference. For about half the translation directions the reference was included as a system to-be-judged by humans; for the rest the red mark is missing. We plot regression lines to indicate Pearson correlation between the two measures. Across all the language pairs it seems there is no visible correlation between LD and direct assessment of MT quality. Pearson correlation across all pairs is about 0.12 for (l)cTTR and 0.21 for (l)cMTLD, i.e. no to weak correlation. For plots with the red marks of the human reference we can now see that only for EN-DE the reference is the most lexically diverse. In the few cases where MT systems are close or better than the reference in terms of MT quality their lexical diversity can be higher and lower. As before, there are enough reasons to be critical about the WMT evaluation methods, but it seems that using LD for QE is not going to happen very soon (unless of course we discover that the human judgments are wrong).
What are the trends over time?
Until now we have collected a number of negative results for our WMT19 data. However, we are using much stronger and technologically newer systems than the papers we discussed earlier. Maybe MT systems have only recently reached their high degree of lexical diversity?
Let’s take a look at a couple of years back: WMT19 is the first year where all the test sets are translated with the correct directionality. Between WMT15 and WMT18, half the test set would have the correct direction and half would have translationese source text with natural target text. The situation seems to be less clear before WMT15. Based on that, I separated the German-English (was English-German before, but into English is reliable now with correct lcTTR and lcMTLD) test sets and the MT outputs from WMT15-18 into corresponding halves and calculate LD for MT vs translationese target text over the past five years, WMT15 to WMT19. During WMT15 only one system (Jean et al. 2015) was a neural system, the rest was SMT or syntax-based. In the following years we can expect a mixed field of competitors, becoming fully neural towards WMT19. Looking at the figure below (click for full size) however we can see, that there is no trend. Even five years ago, LD (via lcTTR) would not have been an MT vs Human discriminator. The picture is similarly random for other languages (plots can be generated with my Makefile by replacing language ids).
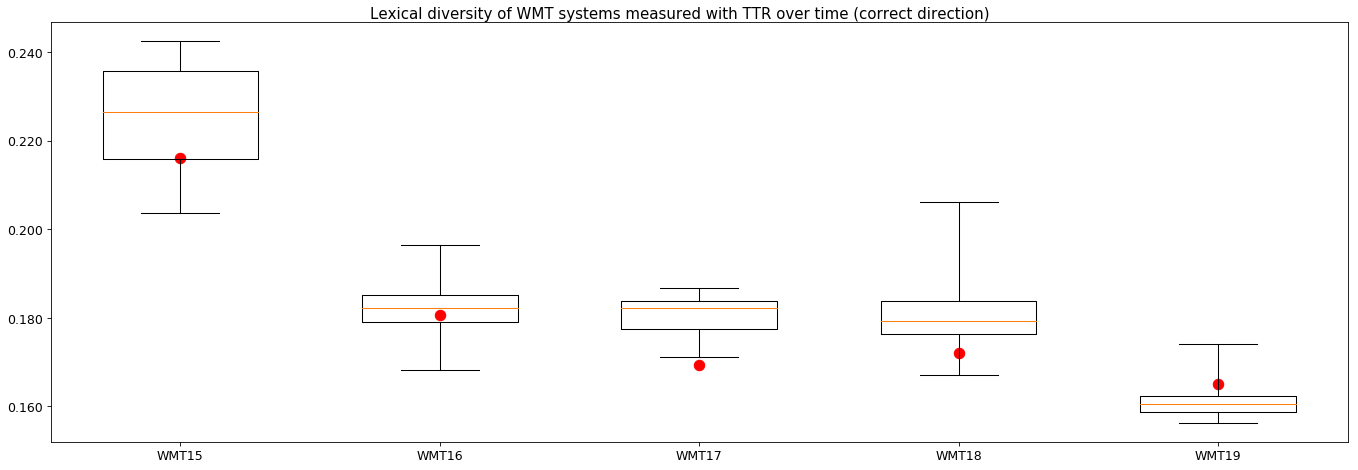
Additional results and plots:
For the years WMT15 to WMT18 we also have the other half of the test sets, the halves with the translationese input and natural target text. Let’s have a look at the figure below for lcTTR (click for full size) what is going on there.
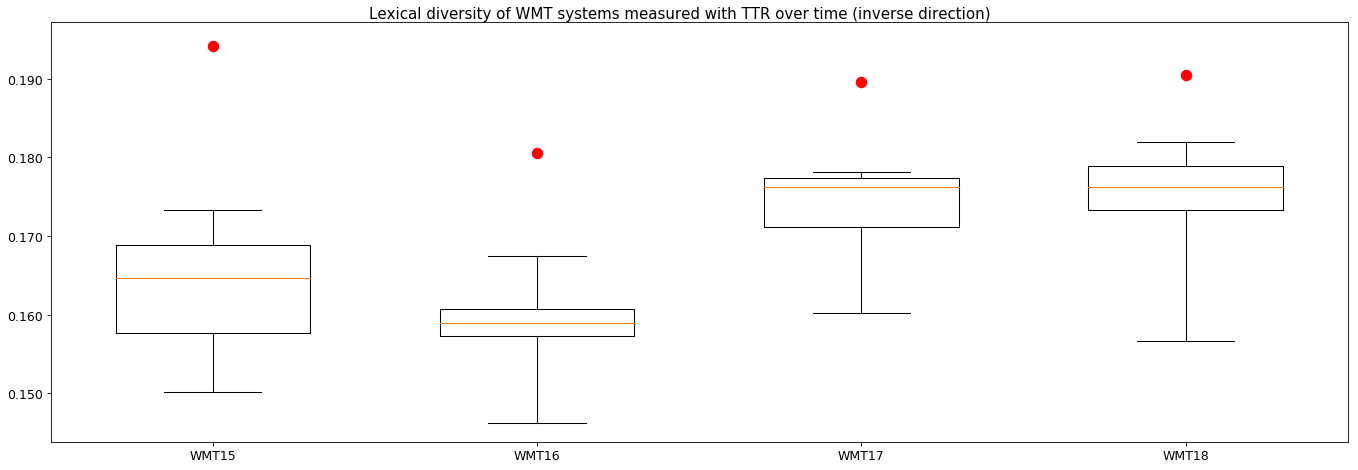
Additional results and plots:
Here we finally see something quite significant: over all four years the natural target is lexically more diverse than all the MT systems, by quite some margin. I verified that this is the case for a number more translation pairs and the results are the same. Unfortunately, in this setup we do not have human-created translations in the mix, so we can only compare apples to slightly different apples across the different time-based plots.
Conclusions?
What can we conclude? A number of things:
- Getting lexical diversity right for MT systems that exist in the wild is hard, and we probably only succeeded for half the systems (until Twitter disproves me on that again).
- Nevertheless, the previous results seem to remain valid, for WMT data and systems specifically there seems to be no indication that WMT test sets created by humans are lexically more diverse than WMT systems; they actually seem to fall into the same ballpark. English-German however is an interesting case that would deserve more attention.
- There seems to be no larger difference or change in trend across the years while moving from SMT to NMT.
- There seems to be no meaningful correlation between the lexical richness of MT and its human-judged quality, whether in source-based or reference-based human-eval scenarios.
- Better-quality MT system might be more reliable candidates for correct lexical diversity calculation, as there seems to be way less noise.
- Natural text is clearly more diverse than MT output, but this comes with a BIG gotcha for WMT: These MT systems translated from source translationese which is likely to be less diverse than natural text, so that would possibly result in a double loss of lexical richness, first by human, next by machine. It might be unfair to judge the MT systems based on that.
So, can LD be useful for anything? Hard to say for now. I see some hope for identifying natural text versus translationese, whether it comes from machines or humans.
As for the main question from the post title: I think we need to be precise that the lexical diversity of WMT outputs is similar to that of WMT test set references. There is the very real possibility that WMT translations are of a lower quality than other translations although they have been ordered from professional agencies etc. I have no evidence for or against that. However, these results also mean that claims of generally lower lexical diversity for MT are potentially doubtful. For one of the most important and biggest MT competitions and its test sets they would be wrong.
I would like to especially emphasize this point: Better-quality MT system might be more reliable candidates for correct lexical diversity calculation as there seems to be way less noise. This might be something that deserves its own blog post. Something like: How good does your MT system need to be in order to be able to reason about MT?
OK, that’s it.
Comments
To comment, you must sign in to your GitHub account below and authorize the utterances app to post in your behalf, or post on the GitHub issue #26 directly.