MarianNMT
Fast Neural Machine Translation in C++
Features & Benchmarks
Features
Overview
- Pure C++ implementation
- One engine for GPU/CPU training and decoding
- Fast multi-GPU training and batched translation on GPU/CPU
- Minimal dependencies on external software: CUDA or MKL, and Boost (soon to be removed)
- Static compilation: compile once, copy the binary and use anywhere
- Permissive MIT license
Model features
- Deep RNNs with Deep Transition Cells (Miceli Barone et al. 2017)
- Transformer models (Vaswani et al. 2017)
- Multi-source models (Junczys-Dowmunt and Grundkiewicz, 2017)
- RNN and transformer-based language models
- Other features: layer normalization (Ba et al. 2016), tied embeddings (Press and Wolf, 2017), residual/skip connections
Training features
- Training on raw texts using built-in SentencePiece for data processing
- Dynamically sized mini-batches for maximum memory usage
- Asynchronous/synchronous multi-GPU training
- Large mini-batches even on a single GPU via cumulative/delayed updates
- Regularization methods: dropout (Gal and Ghahramani, 2016), exponential and smoothing
- Transfer learning from monolingual data, and pre-trained embeddings from word2vec vectors
- Guided alignment for attention
- Sentence-level and word-level data weighting
- Decaying and warmup strategies for learning rate
- Efficient multi-GPU validation and in-training translation
Translation features
- Batched translation on single and multiple GPU/CPUs
- Ensembles of models of different types
- Generating word alignments and attention output
- Rescoring n-best lists and parallel files
- C++ web-socket server
Benchmarks
Translation speed
The models used for the translation speed benchmarks have been described in the IWSLT paper.
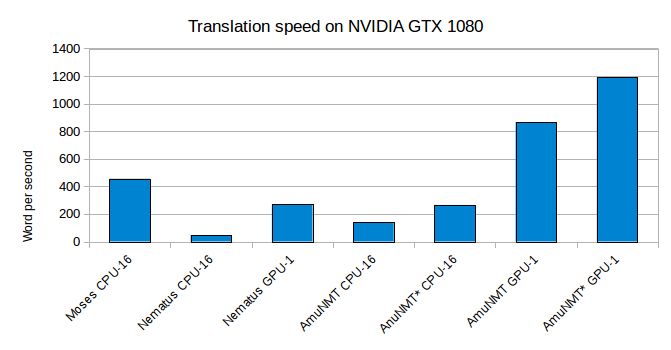
We ran our experiments on an Intel Xeon E5-2620 2.40GHz server with four NVIDIA GeForce GTX 1080 GPUs. We present the words-per-second ratio for our NMT models using Amun and Nematus, executed on the CPU and GPU. For the CPU version we use 16 threads, translating one sentence per thread. We restrict the number of OpenBLAS threads to 1 per main Nematus thread. For the GPU version of Nematus we use 5 processes to maximize GPU saturation. As a baseline, the phrase-based model reaches 455 words per second using 16 threads.
The CPU-bound execution of Nematus reaches 47 words per second while the GPU-bound achieved 270 words per second. In similar settings, CPU-bound Marian is three times faster than Nematus CPU, but three times slower than Moses. With vocabulary selection (systems with asteriks) we can nearly double the speed of Amun CPU. The GPU-executed version of Amun is more than three times faster than Nematus and nearly twice as fast as Moses, achieving 865 words per second, with vocabulary selection we reach 1,192. Even the speed of the CPU version would already allow to replace a Moses-based SMT system with an Marian-based NMT system in a production environment without severely affecting translation throughput.
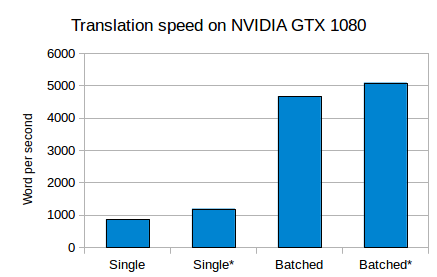
Amun also features “batched” translation, i.e. multiple sentences are being translated at once on a single GPU. Since computation time for matrix products on the GPU increases sub-linearly with regard to matrix size, we can take advantage of this by pushing multiple translation through the neural network. For the same models as above and a batch-size of 200 (beam-size 5) we achieve over 5000 words per second on one GPU. This scales linearly to the number of GPUs used. As before, the asteriks marks systems with vocabulary filtering. Systems “Single” and “Single*” are the same as two best systems in the first graph.
Training speed
We also compare training speed between a number of popular toolkits and Marian (v.1.0.0). The numbers reported in this section have been computed on a single GPU.
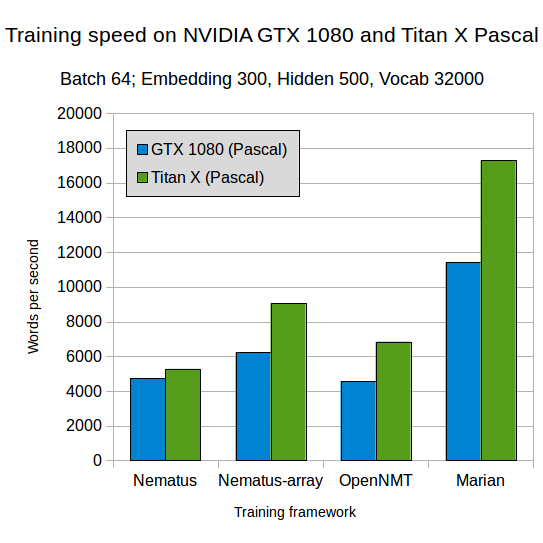
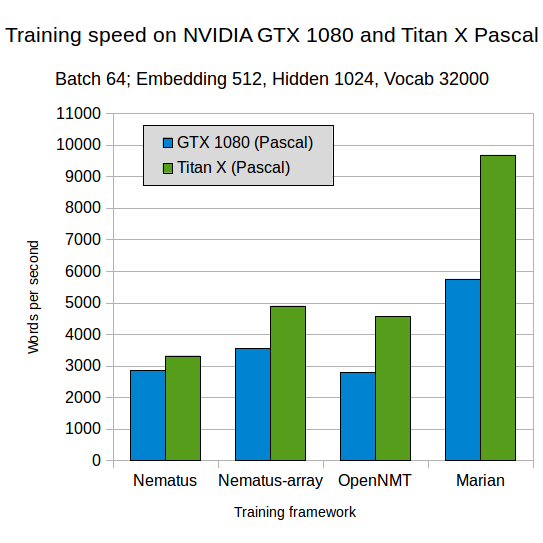
We compare models with standard settings and comparable embedding, hidden layer and batch sizes. The first graph corresponds to the model parameters described in the OpenNMT paper, the second corresponds to Nematus default settings for embedding and hidden layer sizes. In both cases we use a vocabulary size of 32,000 subword units. The models were trained on German-English WMT data. Nematus-array is Nematus run with the new Cuda backend libgpuarray. Blue bars describe training speed on a NVIDIA GTX 1080 GPU, green bars on a Titan X with Pascal architecture.
Multi-GPU training
We demonstrate the training speed as thousands of source tokens per second for different model types trained with Marian v1.5 (see the Marian demonstration paper for more details).
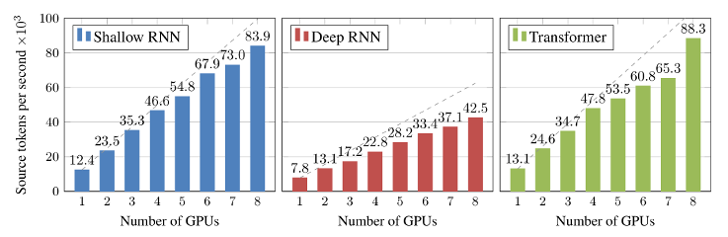
All model types benefit from using more GPUs. Scaling is not linear (dashed lines), but close. The tokens-per-second rate (w/s) for Nematus on the same data on a single GPU is about 2800 w/s for the shallow model. Nematus does not have multi-GPU training. Marian achieves about 4 times faster training on a single GPU and about 30 times faster training on 8 GPUs for identical models.